System Architecture#
Below are sections presenting details of the Gateway Provisioners internals and other related items. While we will attempt to maintain its consistency, the ultimate answers are in the code itself.
Gateway Provisioners#
Gateway provisioner classes derive from the abstract base class
KernelProvisionerBase -
which defines abstract methods for managing the kernel process’s lifecycle. There are two immediate subclasses of
KernelProvisionerBase - LocalProvisioner
(provided by jupyter_client) and RemoteProvisionerBase -
the base class of all Gateway Provisioners’ provisioners.
LocalProvisioner is essentially a pass-through to the current implementation. Kernel specifications that do not contain
a process_proxy stanza will use LocalProvisioner.
RemoteProvisionerBase is an abstract base class representing remote kernel processes. Currently, there are five
built-in subclasses of RemoteProvisionerBase:
DistributedProvisioner- largely a proof of concept class,DistributedProvisioneris responsible for the launch and management of kernels distributed across an explicitly defined set of hosts using ssh. Hosts are determined via a round-robin algorithm (that we should make pluggable someday).YarnProvisioner- is responsible for the discovery and management of kernels hosted as Hadoop YARN applications within a managed cluster.KubernetesProvisioner- is responsible for the discovery and management of kernels hosted within a Kubernetes cluster.SparkOperatorProvisioner- is responsible for the discovery and management of kernels hosted within a Kubernetes cluster that are provisioned via the Custom Resource Definition (CRD)SparkApplication.DockerSwarmProvisioner- is responsible for the discovery and management of kernels hosted within a Docker Swarm cluster.DockerProvisioner- is responsible for the discovery and management of kernels hosted within Docker configuration.
Attention
Because DockerProvisioner kernels will always run local to the corresponding host application instance, these
provisioners are of limited use from a resource optimization standpoint.
You might notice that the last four provisioners do not necessarily control the launch of the kernel. This is because the native Jupyter framework is utilized such that the script that is invoked by the framework is what launches the kernel against that particular resource manager. As a result, the startup time actions of these remote provisioners is dedicated to discovering where the kernel landed within the cluster. Discovery typically consists of using the resource manager’s API to locate the kernel whose “identifier” includes its kernel ID in some fashion.
On the other hand, the DistributedProvisioner essentially wraps the kernel specification’s argument vector (i.e.,
invocation string) in a remote shell since the host is determined by Gateway Provisioners, eliminating the discovery
step from its implementation.
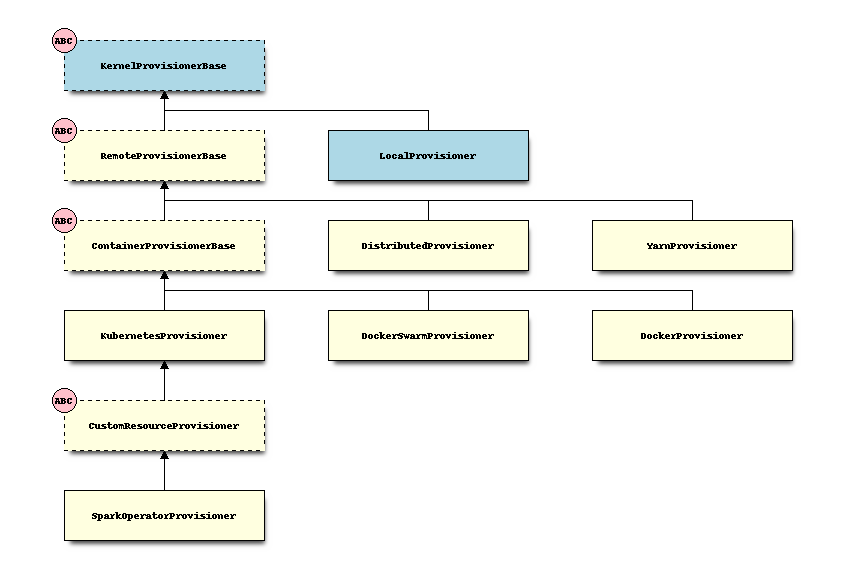
Gateway Provisioner Class Hierarchy#
The following block diagram depicts the current class hierarchy for the Gateway Provisioners. The blocks with an
ABC badge and dashed border indicate abstract base classes. Those light blue blocks come from jupyter_client,
while the others reside in Gateway Provisioners.
RemoteProvisionerBase#
As noted above, RemoteProvisionerBase is an abstract base class that derives from KernelProvisionerBase. Subclasses
of RemoteProvisionerBase must also implement confirm_remote_startup() and log_kernel_launch(), and are
encouraged to override handle_launch_timeout():
@abstractmethod
async def confirm_remote_startup(self):
"""Confirms the remote process has started and returned necessary connection information."""
@abstractmethod
def log_kernel_launch(self, cmd: List[str]) -> None:
"""Logs the kernel launch from the respective remote provisioner"""
async def handle_launch_timeout(self):
"""
Checks to see if the kernel launch timeout has been exceeded while awaiting connection info.
"""
YarnProvisioner#
As part of its base offering, Gateway Provisioners provides an implementation of a kernel provisioner that communicates with the Hadoop YARN resource manager that has been instructed to launch a kernel on one of its worker nodes. The node on which the kernel is launched is up to the resource manager - which enables an optimized distribution of kernel resources.
Derived from RemoteProvisionerBase, YarnProvisioner uses the yarn-api-client
library to locate the kernel and monitor its lifecycle. However, once the kernel has returned its connection
information, the primary kernel operations naturally take place over the ZeroMQ ports.
This provisioner is reliant on the c.YarnProvisioner.yarn_endpoint configurable option or the GP_YARN_ENDPOINT
environment variable to determine where the YARN resource manager is located. To accommodate increased flexibility,
the endpoint definition can be defined within the process proxy stanza of the kernel specification, enabling the
ability to direct specific kernels to different YARN clusters.
In cases where the YARN cluster is configured for high availability, then the c.YarnProvisioner.alt_yarn_endpoint
command line option or the GP_ALT_YARN_ENDPOINT environment variable should also be defined. When set, the
underlying yarn-api-client library will choose the active Resource Manager between the two.
Note
If the host application is running on an edge node of the cluster and has a valid yarn-site.xml file in
HADOOP_CONF_DIR, neither of these values are required (default = None). In such cases, the yarn-api-client
library will choose the active Resource Manager from the configuration files.
See also
Hadoop YARN deployments for deployment details.
YarnProvisionerconfiguration options for other options.
DistributedProvisioner#
Like YarnProvisioner, Gateway Provisioners also provides an implementation of a basic
remoting mechanism that is part of the DistributedProvisioner class. This class
uses the c.DistributedProvisioner.remote_hosts configuration option (or GP_REMOTE_HOSTS
environment variable) to determine on which hosts a given kernel should be launched. By default,
DistributedProvisioner uses a basic round-robin algorithm to determine the target
host of those configured in remote_hosts. (See Specifying a load-balancing algorithm
for other options.) It then uses ssh to launch the kernel on
the selected target host. As a result, all kernel specification files must reside on the remote
hosts in the same directory structure as on the host application server.
It should be noted that spark-based kernels launched with DistributedProvisioner run in YARN client mode -
so their resources (within the kernel process itself) are not managed by the Hadoop YARN resource manager.
Like the yarn endpoint parameter the remote_hosts parameter can be specified within the
kernel provisioner configuration to override the global value, enabling finer-grained kernel distributions.
See also
Distributed deployments in the Operators Guide for details.
ContainerProvisionerBase#
ContainerProvisionerBase is an abstract base class that derives from RemoteProvisionerBase. It implements all
the methods inherited from RemoteProvsionerBase interacting with the container API and requiring method implementations
to perform the platform’s integration. Subclasses
of ContainerProvisionerBase must also implement get_initial_states(), get_error_states(), get_container_status(),
and terminate_container_resources():
@abstractmethod
def get_initial_states(self) -> Set[str]:
"""Return list of states (in lowercase) indicating container is starting (includes running)."""
@abstractmethod
def get_error_states(self) -> Set[str]:
"""Returns the list of error states (in lowercase)."""
@abstractmethod
def get_container_status(self, iteration: Optional[str]) -> str:
"""Return current container state."""
@abstractmethod
def terminate_container_resources(self, restart: bool = False) -> Optional[bool]:
"""Terminate any artifacts created on behalf of the container's lifetime."""
KubernetesProvisioner#
With the popularity of Kubernetes within the enterprise, Gateway Provisioners provides an implementation
of a kernel provisioner that communicates with the Kubernetes resource manager via the Kubernetes API. Because
kernels managed by KubernetesProvisioner are Kubernetes Pods and have container behaviors, KubernetesProvisioner
derives from ContainerProvisionerBase. Unlike the other offerings, in the case of Kubernetes, the host application
is itself deployed within the Kubernetes cluster as a Service and Deployment.
See also
Kubernetes deployments in the Operators Guide for details.
CustomResourceProvisioner#
Gateway Provisioners also provides an implementation of a kernel provisioner derived from KubernetesProvisioner
called CustomResourceProvisioner.
Instead of creating kernels based on a Kubernetes pod, CustomResourceProvisioner
manages kernels via a custom resource definition (CRD). For example, SparkApplication is a CRD that includes
many components of a Spark-on-Kubernetes application.
CustomResourceProvisioner could be considered a virtual abstract base class that provides the necessary method overrides of
KubernetesProvisioner to manage the lifecycle of CRDs. If you are going to extend CustomResourceProvisioner,
all that should be necessary is to override these custom resource related attributes (i.e. group, version, plural and
object_kind) that define the CRD attributes and its implementation should cover the rest. Note that object_kind is
an internal attribute that Gateway Provisioners uses, while the other attributes are associated with the Kubernetes CRD
object definition.
Note
CustomResourceProvisioner is considered a virtual ABC in that an instance of CustomResourceProvisioner could
be instantiated, but it wouldn’t be usable because it doesn’t define the necessary attribute values
to function. In addition, the class itself doesn’t define any abstract methods (today).
SparkOperatorProvisioner#
A great example of a CustomResourceProvisioner is SparkOperatorProvisioner. As described in the previous section,
it’s implementation consists of overrides of attributes group (e.g, "sparkoperator.k8s.io"), version
(i.e., "v1beta2"), plural (i.e., "sparkapplications") and object_kind (i.e., "SparkApplication").
See also
Deploying Custom Resource Definitions in the Operators Guide for details.
DockerSwarmProvisioner#
Gateway Provisioners provides an implementation of a kernel provisioner that communicates with the Docker Swarm resource
manager via the Docker API. When used, the kernels are launched as swarm services and can reside anywhere in the
managed cluster. The core of a Docker Swarm service is a container, so DockerSwarmProvisioner derives from
ContainerProvisionerBase. To leverage kernels configured in this manner, the host application can be deployed either
as a Docker Swarm service or a traditional Docker container.
A similar DockerProvisioner implementation has also been provided. When used, the corresponding kernel will be
launched as a traditional docker container that runs local to the launching host application. As a result,
its use has limited value to address resource optimization.
See also
Docker and Docker Swarm deployments in the Operators Guide for details.
Gateway Provisioners Configuration#
Each kernel.json’s kernel_provisioner stanza can specify an optional config stanza that is converted
into a dictionary of name/value pairs and passed as an argument to each kernel provisioner’s constructor
relative to the provisioner identified by the provisioner_name entry.
How each dictionary entry is interpreted is completely a function of the constructor relative to that provisioner
class or its superclass. For example, an alternate list of remote hosts has meaning to the DistributedProvisioner but
not to its superclasses. As a result, the superclass constructors will not attempt to interpret that value.
In addition, certain dictionary entries can override or amend system-level configuration values set in the application’s configuration file, thereby allowing administrators to tune behaviors down to the kernel level. For example, an administrator might want to constrain Python kernels configured to use specific resources to an entirely different set of hosts (and ports) that other remote kernels might be targeting in order to isolate valuable resources. Similarly, an administrator might want to only authorize specific users to a given kernel.
In such situations, one might find the following kernel_provisioner stanza:
{
"metadata": {
"kernel_provisioner": {
"provisioner_name": "distributed-provisioner",
"config": {
"remote_hosts": "priv_host1,priv_host2",
"port_range": "40000..41000",
"authorized_users": "bob,alice"
}
}
}
}
In this example, the kernel associated with this kernel.json file is relegated to hosts priv_host1 and priv_host2
where kernel ports will be restricted to a range between 40000 and 41000 and only users bob and alice can
launch such kernels (provided neither appear in the global set of unauthorized_users since denial takes precedence).
For a current enumeration of which system-level configuration values can be overridden or amended on a per-kernel basis see Per-kernel overrides.
See also
Configuration Options in our Operators Guide for an overview of all options.
Kernel Launchers#
As noted above, a kernel is considered started once the launch_process() method has conveyed its connection
information back to the Gateway Provisioner’s server process. Conveyance of connection information
from a remote kernel is the responsibility of the remote kernel launcher.
Kernel launchers provide a means of normalizing behaviors across kernels while avoiding kernel modifications. Besides providing a location where connection file creation can occur, they also provide a ‘hook’ for other kinds of behaviors - like establishing virtual environments or sandboxes, providing collaboration behavior, adhering to port range restrictions, etc.
There are four primary tasks of a kernel launcher:
Creation of the connection file and ZMQ ports on the remote (target) system along with a server listener socket
Conveyance of the connection (and listener socket) information back to the Gateway Provisioner’s host application
Invocation of the target kernel
Listen for interrupt and shutdown requests from the Gateway Provisioner’s server and carry out the action when appropriate
Kernel launchers are minimally invoked with three parameters (all of which are conveyed by the argv stanza of the
corresponding kernel.json file): the kernel’s ID as created by the server and conveyed via the
placeholder {kernel_id}, a response address consisting of the Gateway Provisioner’s server’s IP and port on
which to return the connection information similarly represented by the placeholder {response_address}, and a
public-key used by the launcher to encrypt an AES key that, in turn, encrypts the kernel’s connection information back to the
server and represented by the placeholder {public_key}.
The kernel’s ID is identified by the parameter --kernel-id. Its value ({kernel_id}) is essentially used to build
a connection file to pass to the to-be-launched kernel, along with any other things - like log files, etc.
The response address is identified by the parameter --response-address. Its value ({response_address}) consists of
a string of the form <IPV4:port> where the IPV4 address points back to the Gateway Provisioner’s server - which is
listening for a response on the provided port. The port’s default value is 8877, but can be specified via the
environment variable GP_RESPONSE_PORT.
The public key is identified by the parameter --public-key. Its value ({public_key}) is used to encrypt an
AES key created by the launcher to encrypt the kernel’s connection information. The server, upon receipt of the
response, uses the corresponding private key to decrypt the AES key, which it then uses to decrypt the connection
information. Both the public and private keys are ephemeral; created upon the initial load of Gateway Provisioners.
They can be ephemeral because they are only needed during a kernel’s startup and never again.
Here’s a kernel.json file illustrating these parameters…
{
"argv": [
"python",
"/usr/local/share/jupyter/kernels/k8s_python/scripts/launch_kubernetes.py",
"--kernel-id",
"{kernel_id}",
"--port-range",
"{port_range}",
"--response-address",
"{response_address}",
"--public-key",
"{public_key}",
"--kernel-class-name",
"ipykernel.ipkernel.IPythonKernel"
],
"env": {},
"display_name": "Kubernetes Python",
"language": "python",
"interrupt_mode": "signal",
"metadata": {
"debugger": true,
"kernel_provisioner": {
"provisioner_name": "kubernetes-provisioner",
"config": {
"image_name": "elyra/kernel-py:dev",
"launch_timeout": 30
}
}
}
}
Other options supported by launchers include:
--port-range {port_range}- passes configured port-range to launcher where launcher applies that range to kernel ports. The port-range may be configured globally or on a per-kernel specification basis, as previously described.--spark-context-initialization-mode [lazy|eager|none]- indicates the timeframe in which the spark context will be created.lazy(default) attempts to defer initialization as late as possible - although this can vary depending on the underlying kernel and launcher implementation.eagerattempts to create the spark context as soon as possible.noneskips spark context creation altogether.
Note that some launchers may not be able to support all modes. For example, the scala launcher uses the Apache Toree kernel, which currently assumes a spark context will exist. As a result, a mode of
nonedoesn’t apply. Similarly, thelazyandeagermodes in the Python launcher are essentially the same, with the spark context creation occurring immediately, but in the background thereby minimizing the kernel’s startup time.
The kernel.json files also include a LAUNCH_OPTS section in the env stanza to allow for custom
parameters to be conveyed in the launcher’s environment. LAUNCH_OPTS are then referenced in
the run.sh script (for spark-based kernels) as the initial arguments to the launcher:
eval exec \
"${SPARK_HOME}/bin/spark-submit" \
"${SPARK_OPTS}" \
"${PROG_HOME}/scripts/launch_ipykernel.py" \
"${LAUNCH_OPTS}" \
"$@"
See also
See Implementing a Kernel Launcher in the Developers Guide for additional information.
Extending Gateway Provisioners#
Theoretically speaking, enabling a kernel for use in other frameworks amounts to the following:
Build a kernel specification file that identifies the provisioner class to be used.
Implement the provisioner class such that it supports the four primitive functions of
poll(),wait(),send_signal(signum)andkill()along withlaunch_process(). If this provisioner derives from another, these method implementations can be inherited.If the provisioner corresponds to a remote process, derive the provisioner class from
RemoteProvisionerBaseand implementconfirm_remote_startup()andhandle_launch_timeout().Insert invocation of a launcher (if necessary) which builds the connection file and returns its contents on the
{response_address}socket and following the encryption protocol set forth in the other launchers.
See also
See Implementing a Gateway Provisioner in the Developers Guide for additional information.